[논문 리뷰] MCUNet: Tiny Deep Learning on IoT Devices
본 논문은 MIT Prof. Song Han의 연구실로부터 발표된 논문이다.
소 개
각 환경에 따라 프로그램의 크기는 늘 제약적이다. 그림 1의 MCUNet 소개 자료를 보면 동일한 DL 모델이 환경에따라 제약적이며, MCU의 경우 스마트폰에 비해 대략 13,000배 더욱 작은 메모리 공간을 문제로 두고 있다.

그림 2의 (a)는 학습된 모델을 추론 라이브러리로 모델을 사용하는 방식으로 대부분 TinyML 이나 DL 하면 떠오르는 방식이다. Tensorflow-Lite나 CMSIS-NN이 이 방식을 사용하고 있다. (b)는 학습된 NN모델을 DL 라이브러리를 통해 튜닝하여 성능을 올리는 방식이다. 이 방식은 Micro(μ)TVM에서 사용하는 방식으로 광범위한 장치에서 사용하기 위한 NN 모델을 MCU에 맞도록 만들기 위해 (b)와 같은 방식을 차용했다.
그림 2의 (a), (b)의 두 방식은 DL기능을 End-device에서 사용하기에는 여전히 고사양 MCU를 제한적으로 요구한다. MCUNet은 이 문제점을 해결 하기 위해 학습 모델과 추론 모델이 상호보완적 관계를 형성하였다. 그림 2 (c)는 제안된 프레임워크로 주요 포인트는 MCU에 맞는 Machine Learning(ML)과 DL 모델의 라이브러리를 찾아주는 TinyNAS와 추론을 위한 TinyEngine 두 가지로 구성된다.
※ TinyNAS의 명칭은 MnasNet(MnasNet_Platform)으로 부터 온 Neural AutoSerach(NAS)로 부터 M의 Mobile이 아닌 Tiny 버전으로 명칭을 지은것 이다.

프레임워크의 전체적 구조
TinyNAS는 NN 구조를 먼저 찾고 해당 모델을 Tensorflow-Lite버전 Intermediate Representation(IR) 이후 코드를 생성한다. 생성된 코드는 최대 메모리와 Latency(ms)를 체크하고 NAS 모델로 피드백 하여 최적의 모델을 찾게 한다. 최적의 모델을 찾게 되면 TinyEngine에서는 해당 모델에 대해 MCU에 맞는 추론 코드를 생성한다.

구조 1. TinyNAS: Two-Stage NAS for Tiny Memory Constraints
TinyNAS는 two-stage로 이루어진 NN 색인 방법을 가지고 있다. 첫번째 스테이지는 Automated search space optimization으로 메모리 공간에 따라 다양한 모델을 찾고, 메모리 공간 최적점에 따라 최적의 모델을 찾는다. 이렇게 찾은 모델은 최적화된 공간을 가진 전체적인 정확도를 향상시킨다. 본 논문에서는 이 지점을 S* 라고하며, 최적 모델을 찾는 방식은 MobileNet의 Resolution multiplier와 유사한 Resolution spanning 과 MobileNet의 Width multiplier 를 이용한다. R은 48, 64, 80 ... 192, 208, 224의 8배수인 해상도값, W는 0.2, 0.3 ... 1.0의 파라미터 값이다. 두 파라미터를 이용해 S=R x W 식을 사용하여 총 12x9 = 108개의 모델을 만들어 찾을 수 있다. 따라서 모델 각각의 검색 공간은 총 3.3 x $ 10^{25} $개를 가질 수 있다. 수많은 모델중 최적의 모델을 찾기는 많은 자원이 소모되기에 Cumulative Distribution Function(CDF)를 활용하여 FLOPs만 수집하여 모델을 찾는 시간에 제약사항을 둔다.
그림 4는 width-res에 따른 다양한 모델을 CDF로 표현하였다. 검은선은 정확도가 74.2%로 최저점에 있고, 빨간선은 최고점 78.7%로 4.5%의 차이가 있다. 모델의 mFLOPs를 비교하면 검은선은 32.2M 빨간선은 50.3M 으로 가장 높은 FLOPs를 가진 모델이 가장 높은 정확도를 보였다. 그리고 이중 FLOPs와 정확도를 절충한 초록선이 가장 효율적이며, 가장 최적화된 모델로 선택된다.

두 번째 스테이지는 Resource-constrained model specialization로 메모리 제약에 따라 최적화된 모델을 one-shot architecture search(G. Bender et al. One-Shot Architecture Search.pdf) 방법으로 찾게된다. (저자는 모델 사이즈를 최적화 할 경우 최대 200배 가량 줄일 수 있다고 한다)
TinyNAS의 학습 방법은 거대한 슈퍼 네트워크에서 서브 네트워크를 여러개 만들어 가장 최적화된 모델을 찾게 되는게 핵심이다. 서브 네트워크들은 각각 가중치를 공유하며 각 네트워크별로 성능을 추정한다.
구조 2. TinyEngine: A Memory-Efficient Inference Library
TinyEngine은 MCU에 가장 최적화된 추론 라이브러리를 제공한다. 대부분의 추론 라이브러리(TF-Lite, CMSIS-NN)는 Cross-platform 개발에 용이하게 하기 위해 인터프리터 베이스로 런타임 메모리를 많이 요구하게 된다. 반면 TinyEngine은 TinyNAS로 생성된 모델을 타겟 MCU에 있어 가장 최적화된 코드만 생성하게 된다. 따라서, 런타임 라이브러리를 최소화와 최적화 하여 메모리 공간을 최저로 사용한다. 그림5 와 6는 모델별로 비교하였다. MNasNet 기준으로 Latency는 CMSIS-NN 보다 1.5배 빠르고, 메모리는 2.7배 적게 차지하였다.
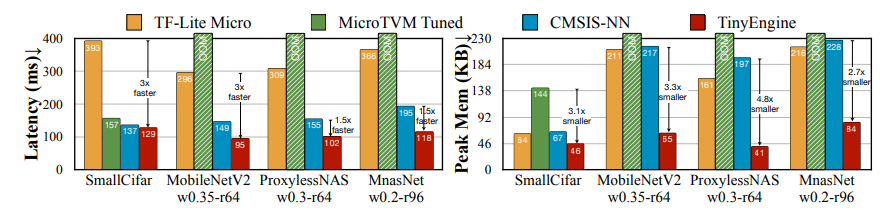

그림 6중 Im2col, Op fusion, Loop unrolling, Tiling 은 각각 메모리 스케줄링(Model-adaptive memory scheduling), 커널 최적화(Computation kernel specialization), 모델 사이즈 최적화(In-place depth-wise convolution)의 기능을 가진다.
Model-adaptive memory scheduling은 기존 추론 라이브러리가 각 레이어에 대해 메모리를 예약하지만 TinyEngine은 가장 큰 버퍼를 지정하고 각 레이어가 실행될때만 해당 메모리 버퍼를 사용하게 된다. Input layer에는 Im2col을 이용하게 되고 Im2col로 이후로 스케줄링 된다. 메모리 버퍼 사이즈인 M은 Layer인 L의 사이즈에 의해 결정된다.


Computation kernel specialization은 레이어에 대해 커널을 최적화 한다. Loops tiling은 다른 커널 크기와 사용 가능한 메모리를 기반으로 한다. Loop unrolling은 분기 명령 오버헤드를 제거하기 위해 다양한 커널 크기를 사용한다. 다양한 커널 크기의 예로는 3x3은 9개의 반복 코드 5x5는 25개의 반복 코드를 가진다.

In-place depth-wise convolution은 peak 메모리를 줄이기 위해 depth-wise 방식을 사용한다. 그림 7에서 (a) 처럼 일반적인 depth-wise 방식은 depth layer만 tensor와 같은 다중 채널이 아닌 단일채널 Feature map을 input과 output으로 사용하지만 in-place depth-wise는 가용 버퍼에서 input과 output을 동시에 사용하여 메모리에 사용되는 Feature map 량을 2N에서 N+1로 줄여서 Peak 메모리 량을 줄였다. 본 논문에서 해당 방법을 이용할 경우 1.6배 줄일 수 있는 효과를 가진다고 한다.
실험 및 결과
실험은 STM-H743 Cortex-M7(512kB SRAM and 2MB Flash) 에서 실험하였고, Pascal VOC 데이터셋과 학습 모델은 YOLOv2를 사용하였다. 표 1은 해당 실험의 결과이다. MobileNetV2와 CMSIS-NN을 이용하였을 경우 SRAM의 최대치를 넘겨 사용이 어렵고 FLOPs가 적은만큼 해상도도 MCUNet에 비해 적다. 무엇보다 Object detection의 정확도 지표인 mAP가 19.8% 크게 차이 났다.

발표영상: https://youtu.be/YvioBgtec4U
Reference: https://arxiv.org/pdf/2007.10319.pdf
GitHub URL: https://github.com/mit-han-lab/tinyml
GitHub - mit-han-lab/tinyml
Contribute to mit-han-lab/tinyml development by creating an account on GitHub.
github.com
※ 본 게시글의 모든 자료는 해당 논문 발표 및 논문에서 발췌해왔음을 명시합니다.